
0. 引子
最近突发奇想想要把我推的 Twitter 账号留一份全量备份,但是搜寻互联网,要么是要借助付费工具,要么就是只能备份自己的账号。
于是乎,本人开发了一套使用开源工具,可以备份任意账号的工作流~

最终效果:
1.准备工作
一台正常的PC设备(安装了 Python 或者 uv
能使用终端执行代码的你
可以访问 X 的互联网
一点点耐心
首先克隆本仓库
git clone https://github.com/zdxiaoda/TwitterBackup.git
本教程默认使用 uv ,对于 pip 的操作大同小异。(如果你不知道 uv 是什么或者没有安装 uv ,可以参见官方文档进行安装)
进入仓库文件夹后运行同步指令安装依赖
uv sync
依赖安装完成后,准备工作结束。
2.下载数据
此处我们使用 gallery-dl 这个开源程序获取 X 的数据,包括媒体数据和推文数据。
确保你依然将工作目录设置在本仓库,因为 uv 已经安装了这个包,所以直接执行即可。
首先需要创建对于 X 下载的配置文件,由于程序默认不会保存推文和用户数据,所以需要先进行配置。
Windows 用户:%APPDATA%\gallery-dl\config.json
%APPDATA% 在哪?
按下 Win + R 键(Windows 徽标键 + R),打开“运行”窗口。
在弹出的窗口中输入 %APPDATA%,然后按下回车键。
文件资源管理器会自动打开 %APPDATA% 对应的文件夹。
Linux/Mac 用户:${HOME}/.config/gallery-dl/config.json
${HOME} 在哪?
打开终端。
在终端中输入 echo $HOME,然后回车。
终端会显示用户主目录路径。
根据你的系统创建配置文件后,复制如下内容。
{
"extractor": {
"twitter": {
"text-tweets": true,
"include": "timeline",
"videos": true,
"retweets": true,
"quoted": true
}
},
"downloader": {
"http": {
"rate": "1M"
}
},
"output": {
"mode": "terminal",
"progress": true
},
"postprocessors": [
{
"name": "metadata",
"mode": "json",
"extension": "json",
"directory": ["twitter-meta"],
"indent": 4,
"event": "post",
"filename": "{tweet_id}.json"
}
]
}
随后需要获取一个 X 账号的 Cookie,推荐使用扩展程序直接导出。
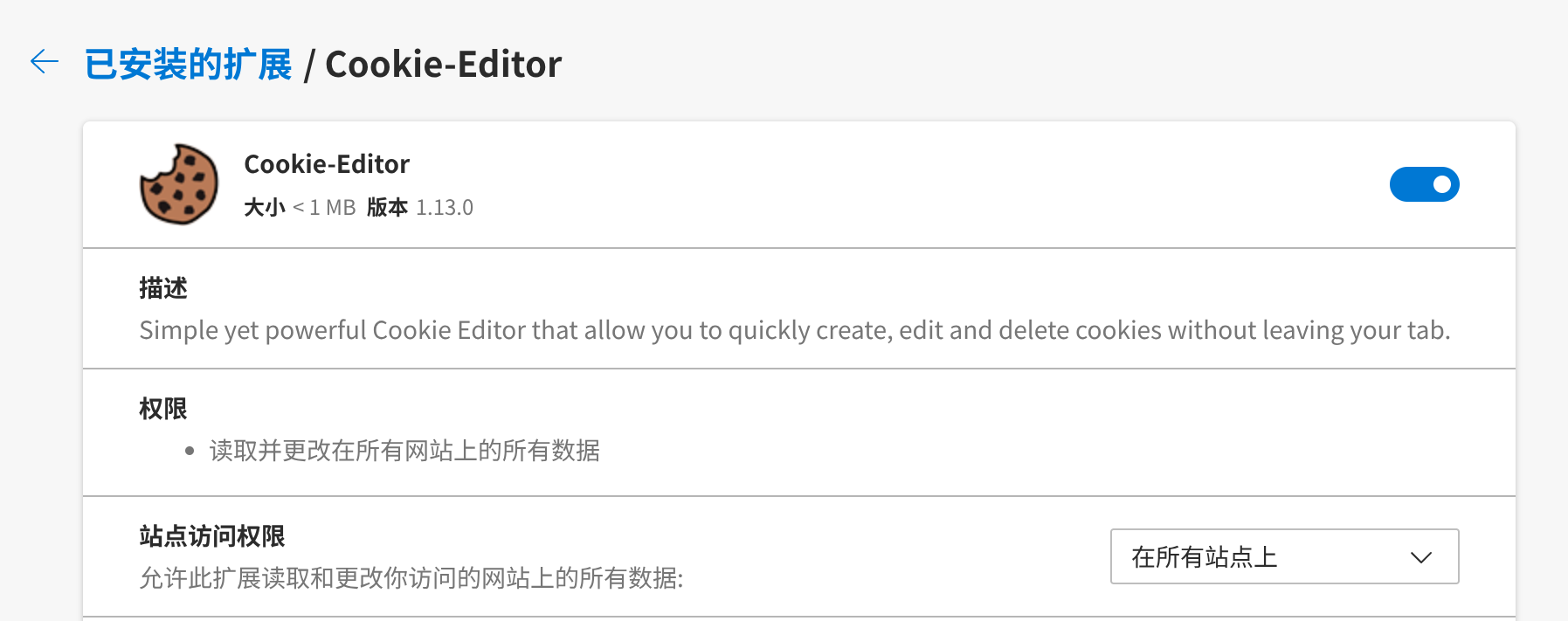
安装扩展后登录 X.com 打开扩展
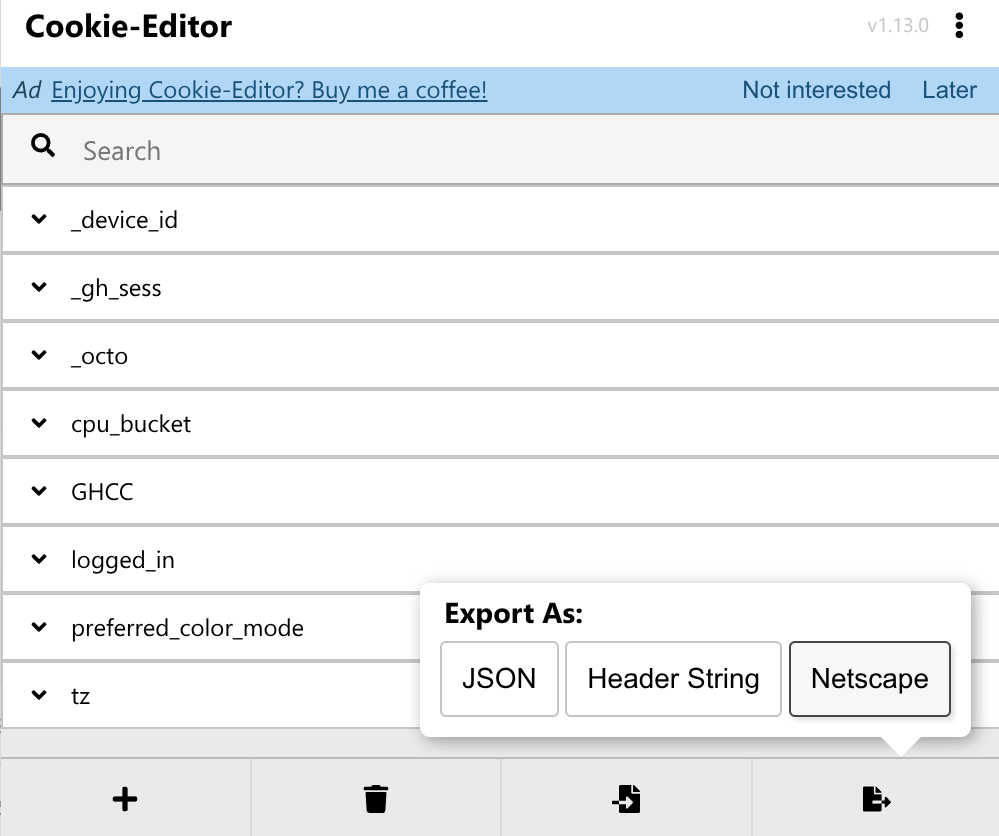
随后在工作文件夹创建 cookie.txt ,粘贴剪切板中的 cookie🍪,就可以开始下载了。
比方说,下载指定用户的所有内容。
uv run gallery-dl https://x.com/用户名 --cookies 'cookie.txt路径'
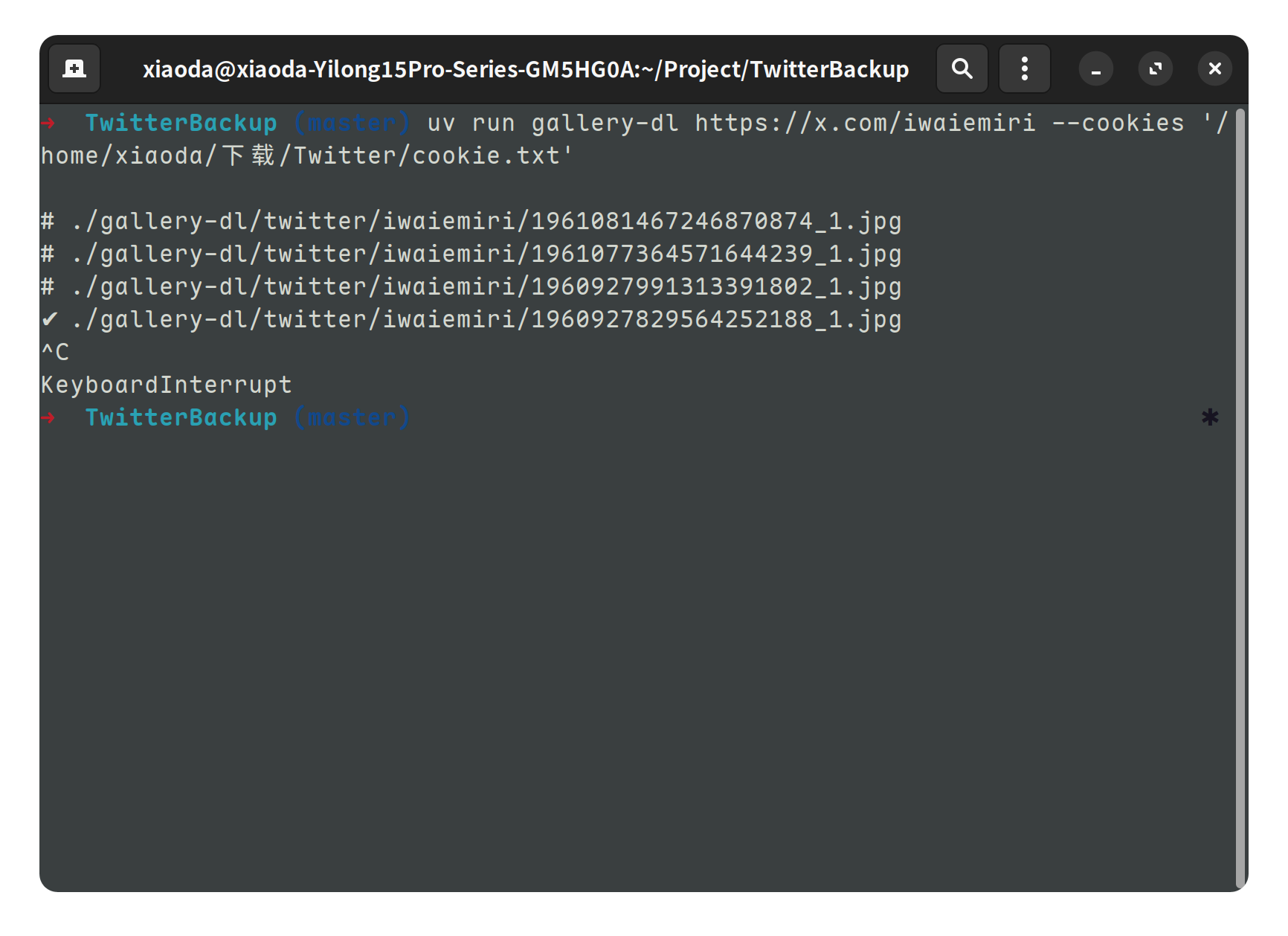
下载后的文件存储在 ./gallery-dl/twitter/用户名/ 文件夹
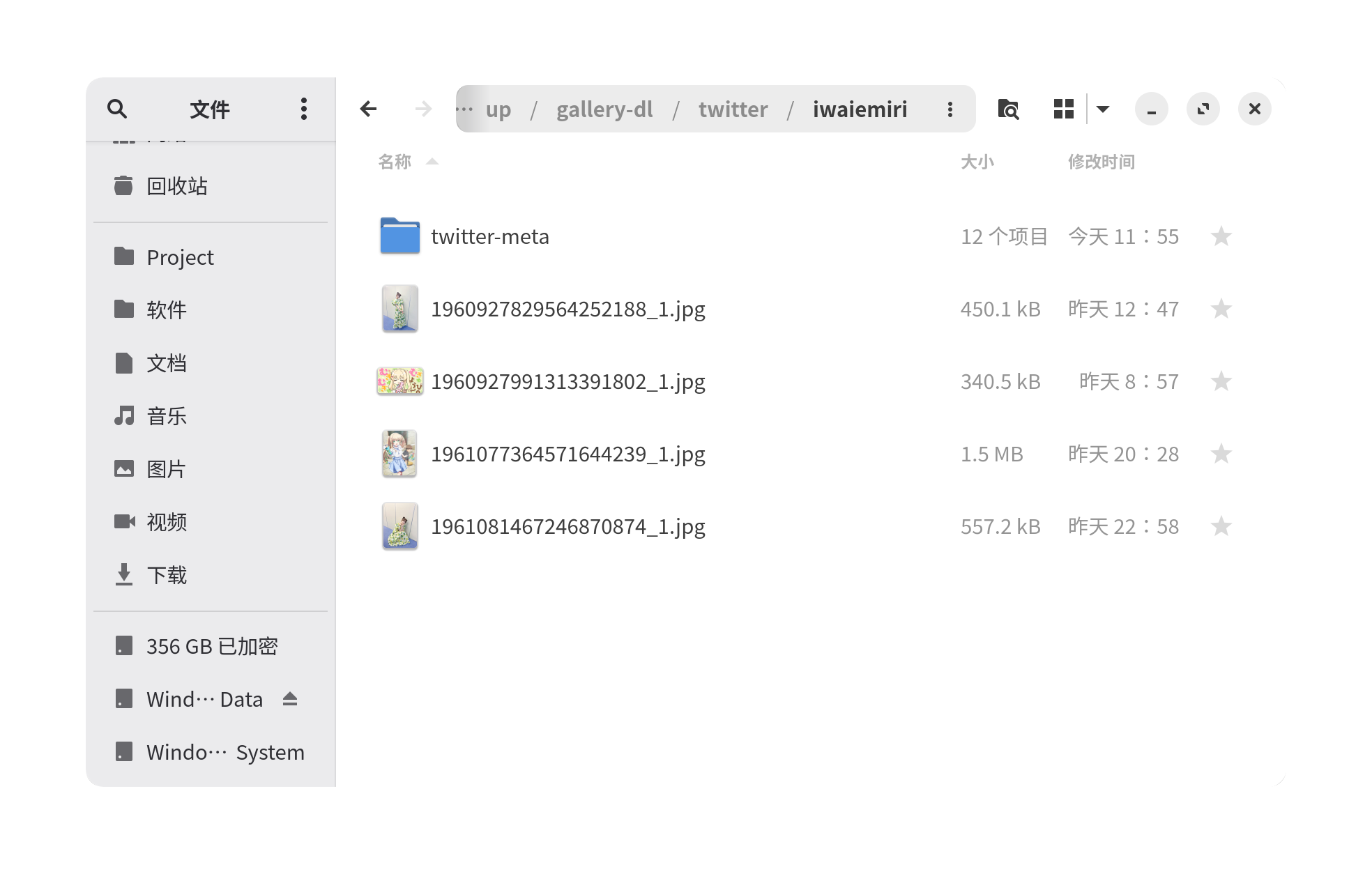
3.数据处理
通过此办法下载的内容如果数据量小还好,当推文数量庞大(这是能轻易做到的)时,数据的查找就变得极其困难。

因此本仓库也准备了数据处理脚本,可以将 json 转存 sqlite3 数据库当中,方便之后的展示和数据分析。
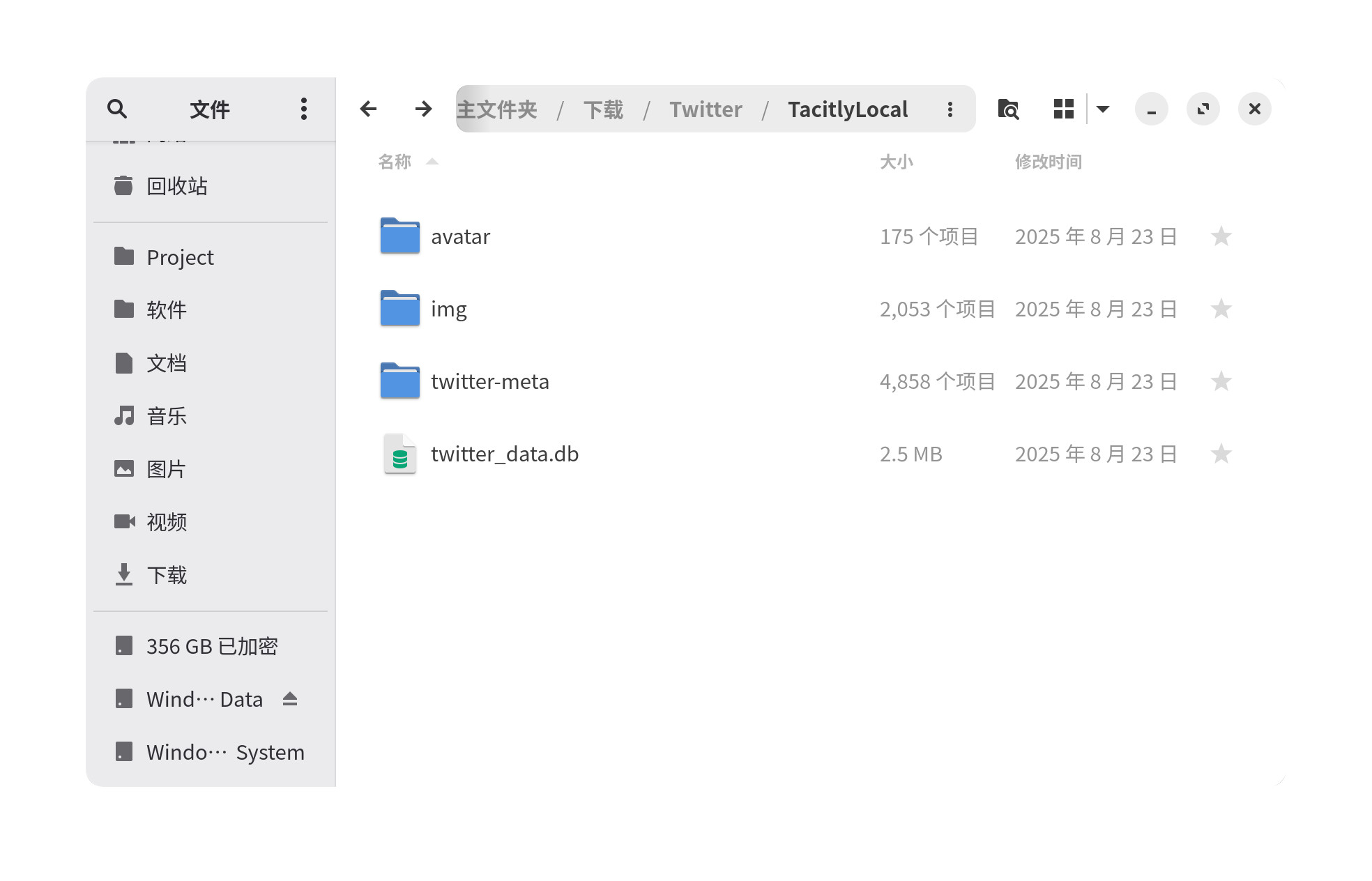
第一步进入下载的数据文件夹,把所有的图片/视频剪切到一个名为 img 的子文件夹中。
随后进入仓库,运行命令。
uv run twitter_data_processor.py 数据路径
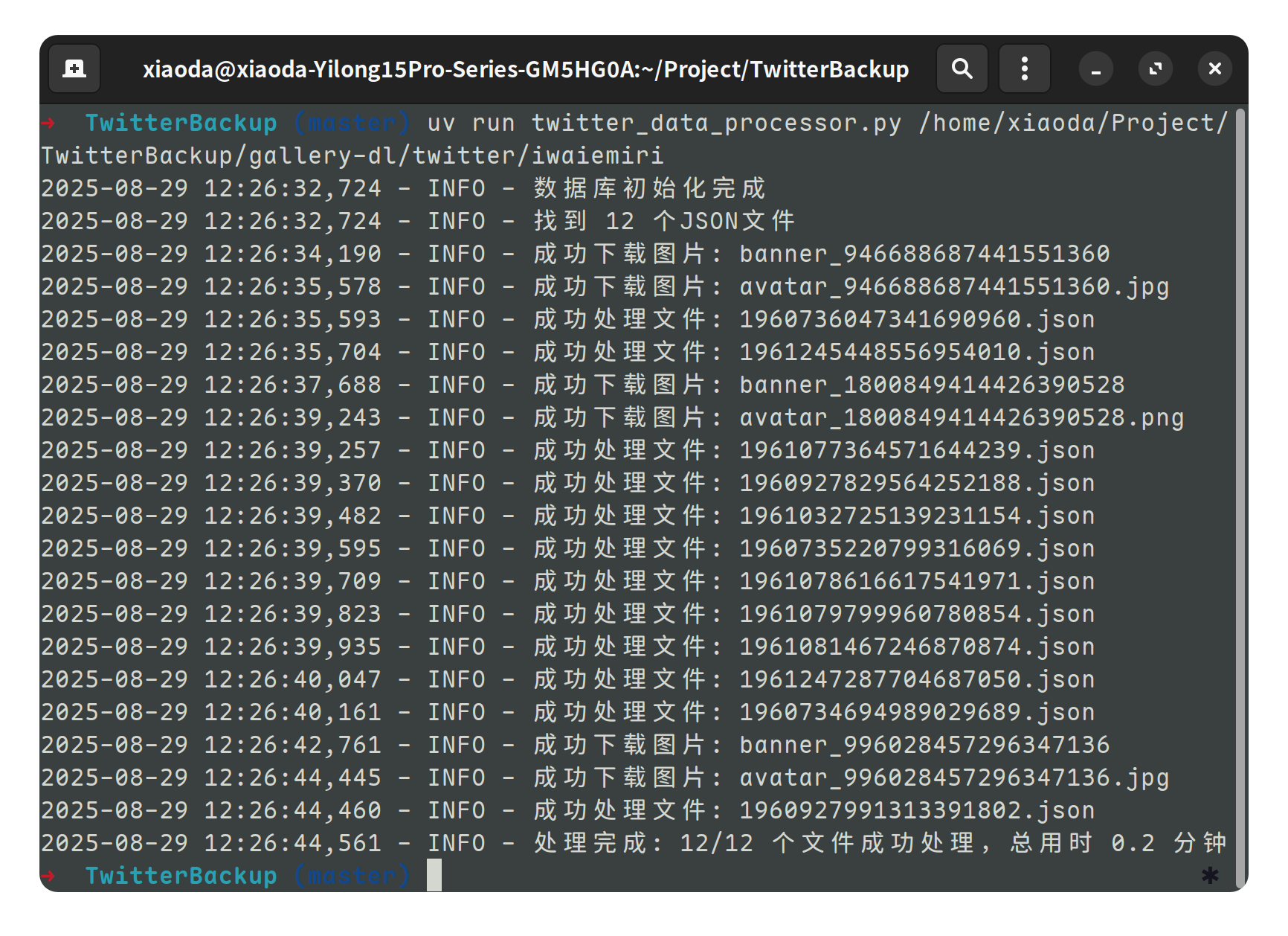
程序会自动创建数据库并且下载此前没有下载的用户 banner 和 avatar 图片,也会将 img 文件夹的媒体关联到对应的推文中。而且在创建数据库完成后也支持增量备份,也就是说你可以将不同的用户的数据放置到同一个数据库。
最后你会得到形如图片中的目录结构
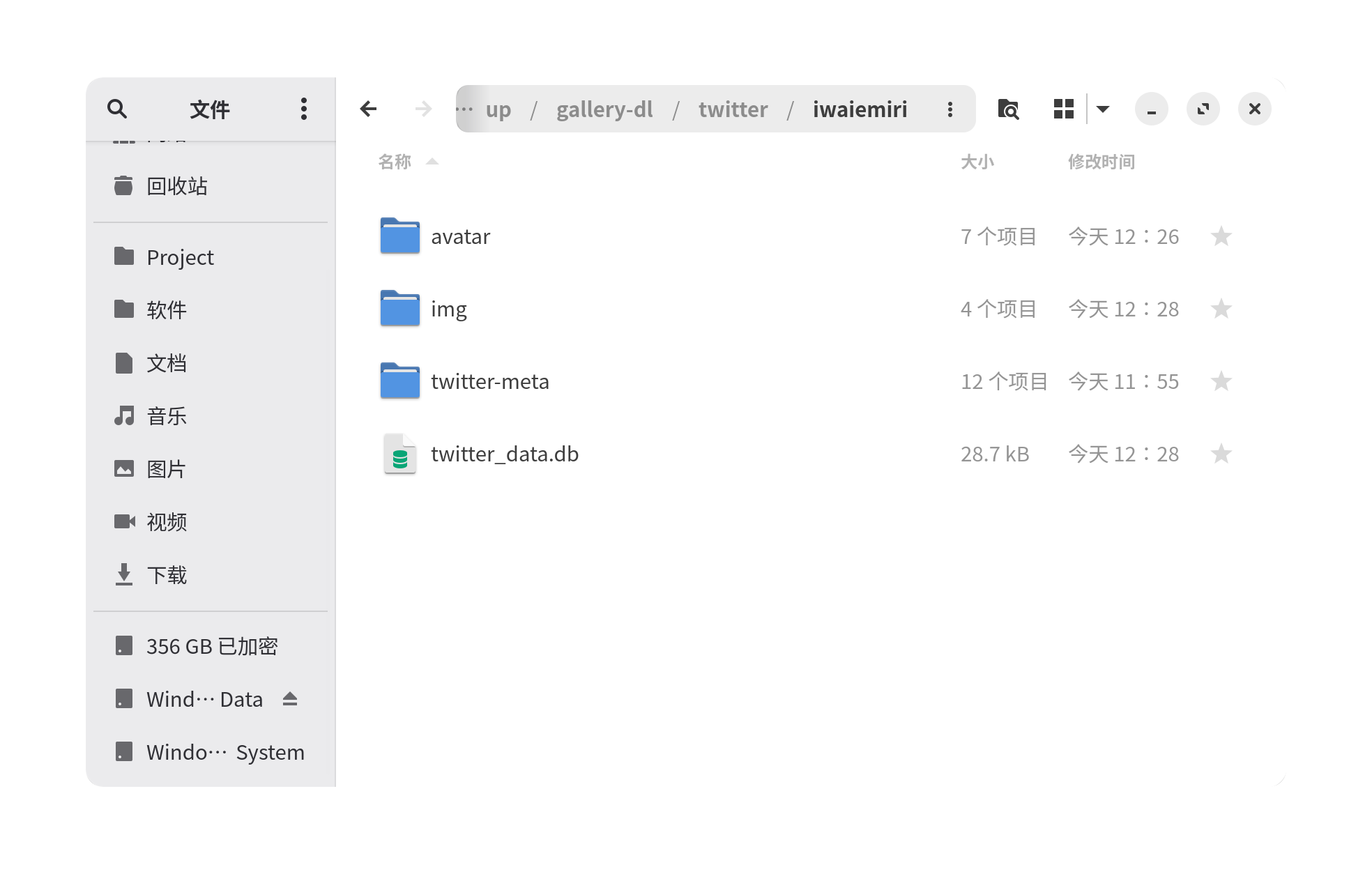
4.数据展示
还是本仓库,可以通过运行 main.py 脚本对数据库的内容进行展示。
uv run main.py 'twitter_data.db 路径'
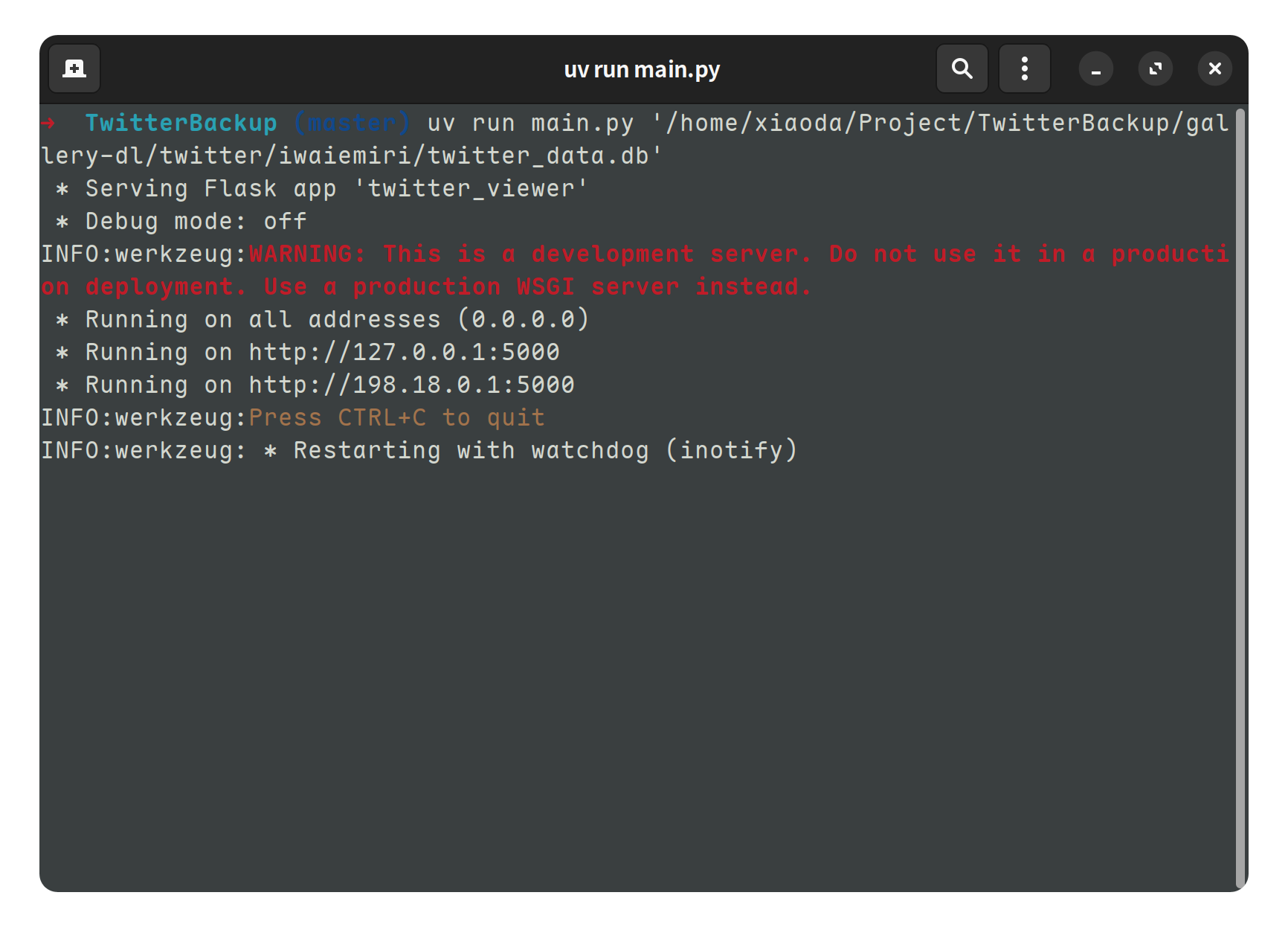
随后访问 http://127.0.0.1:5000 即可图形化查看备份的推文。
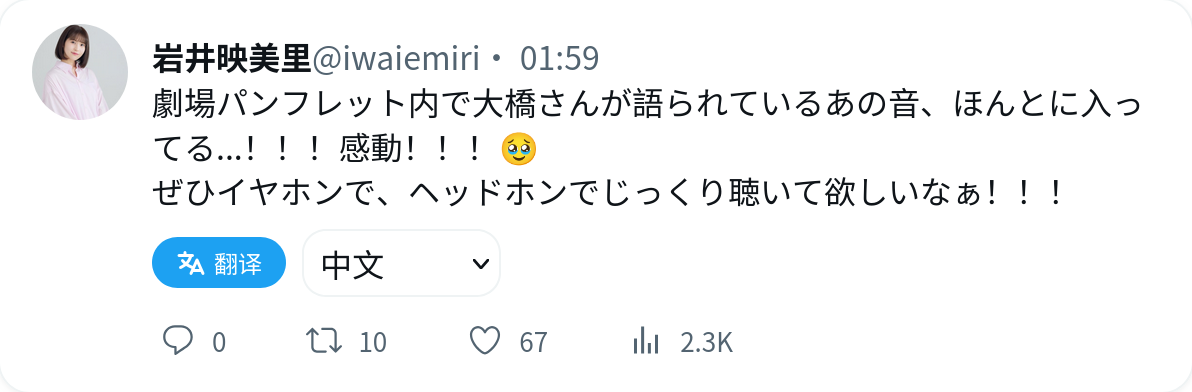
包括纯文本推文:
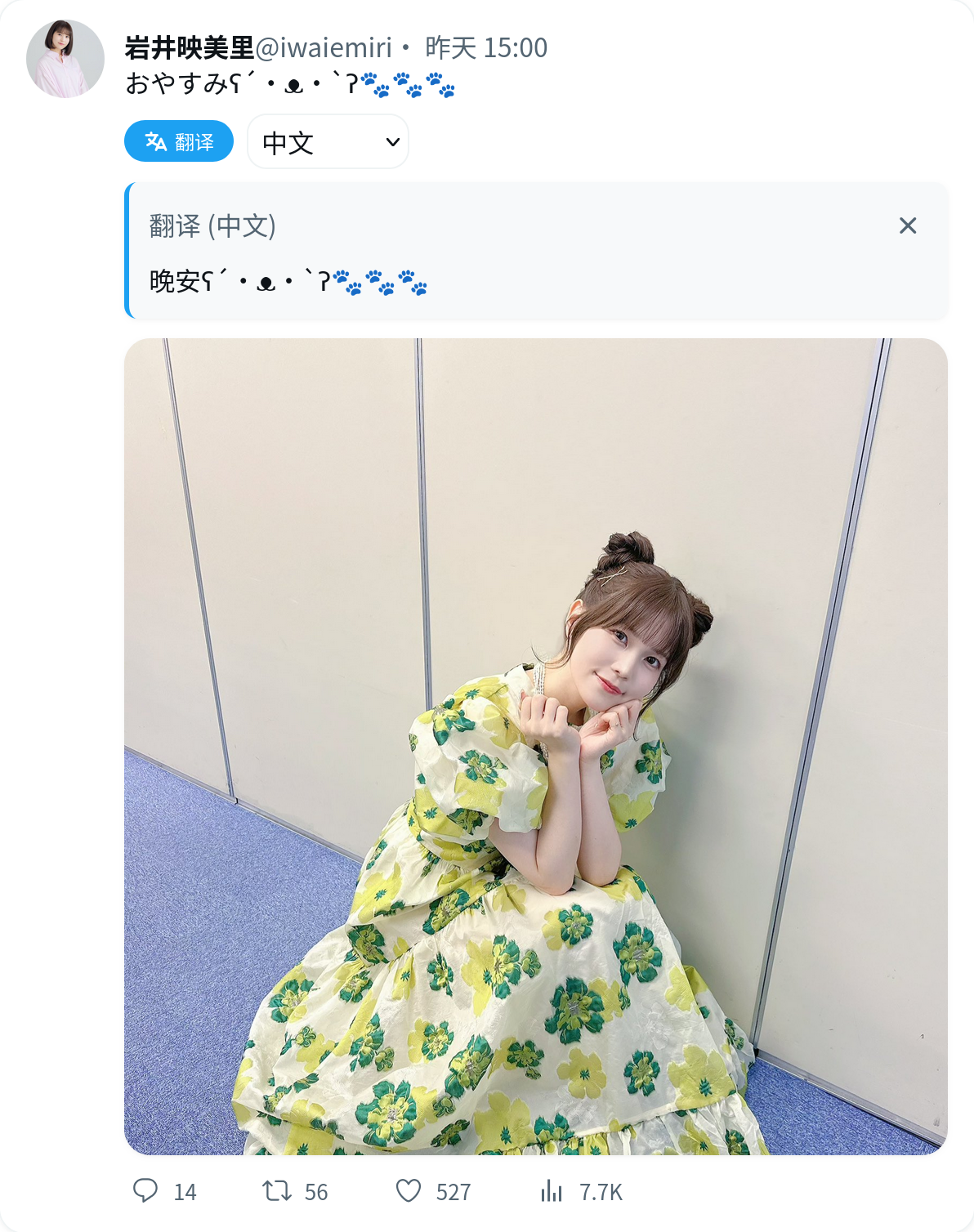
媒体文件推文:
转发推文:
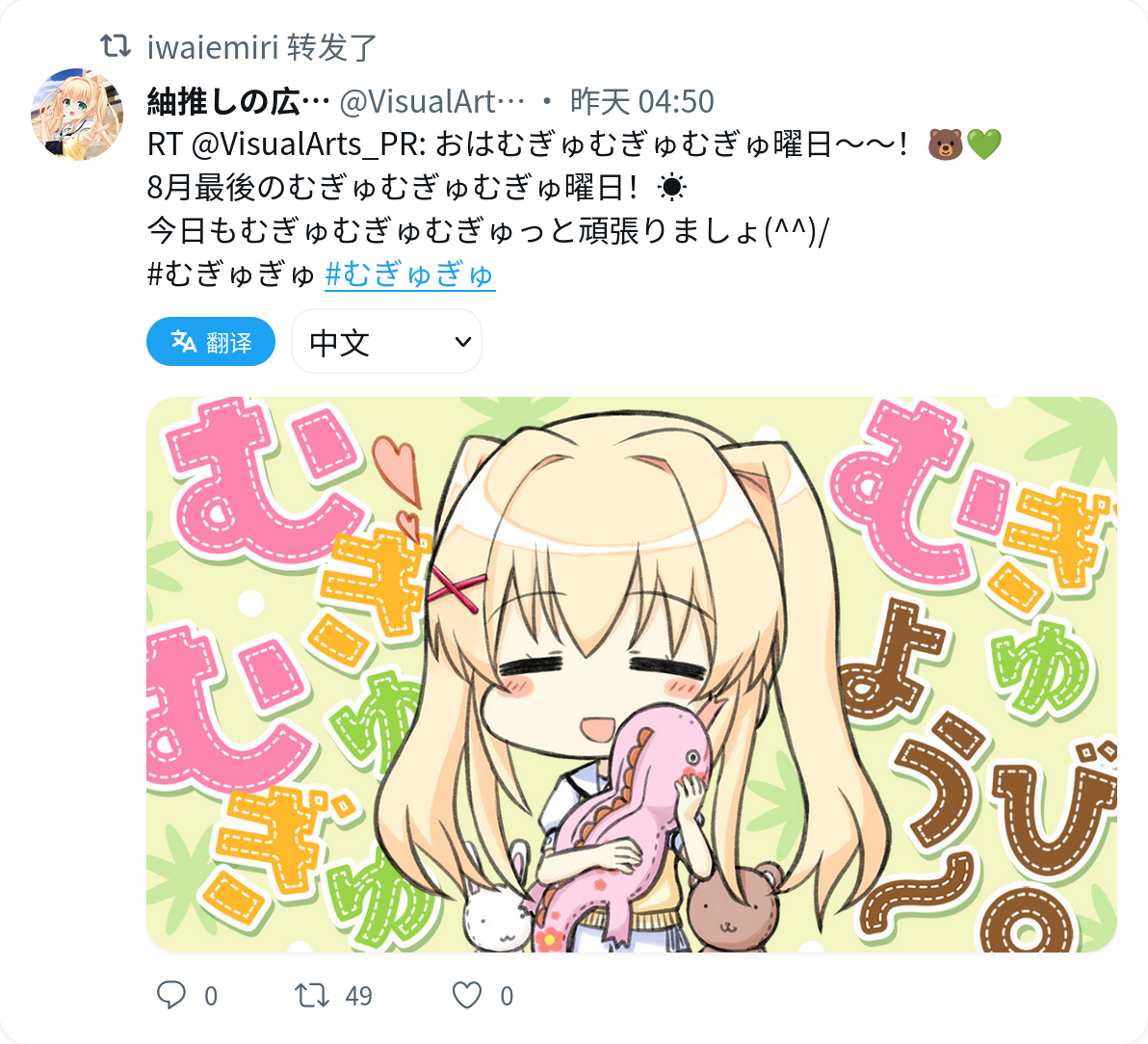
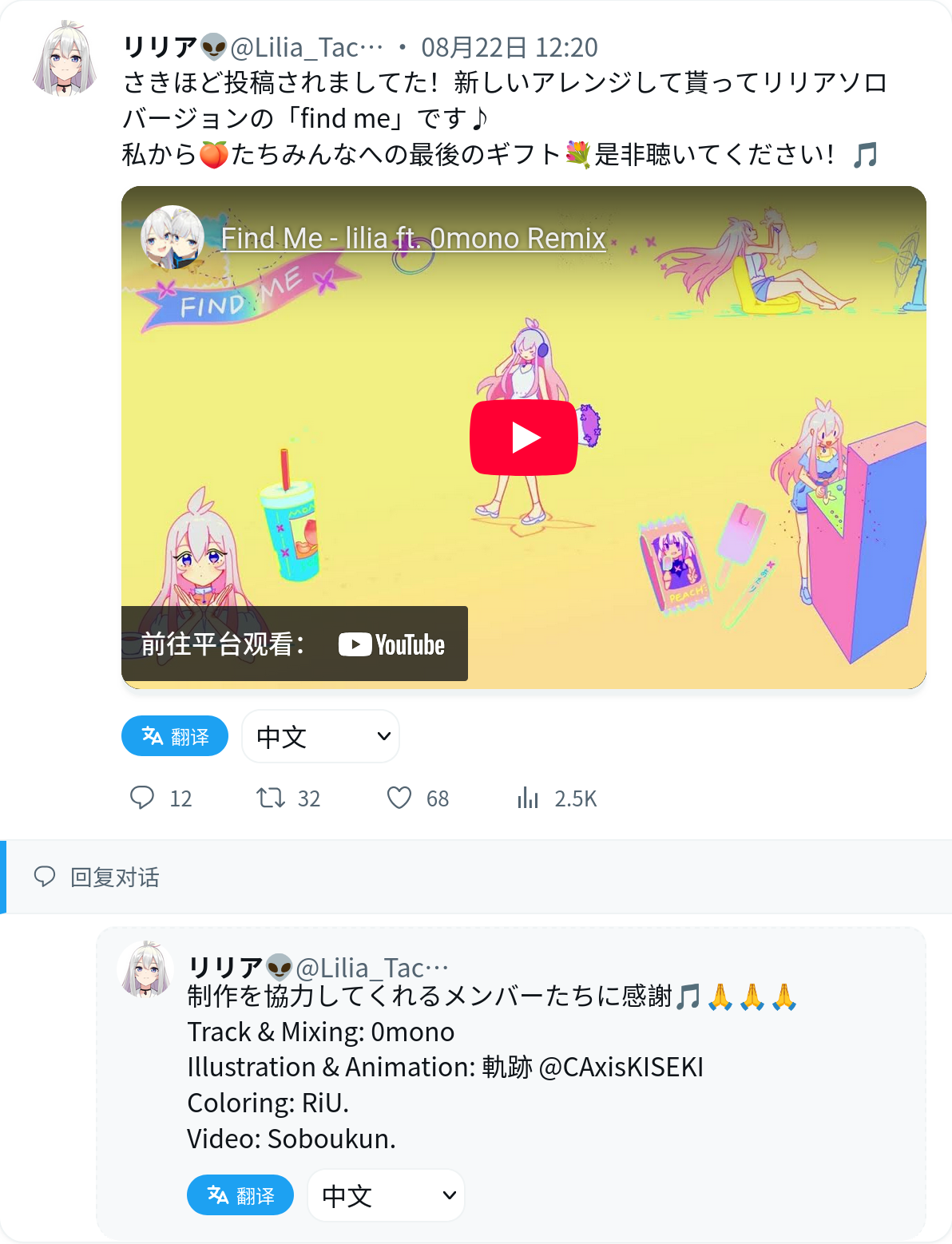
回复推文和 Youtube 视频:
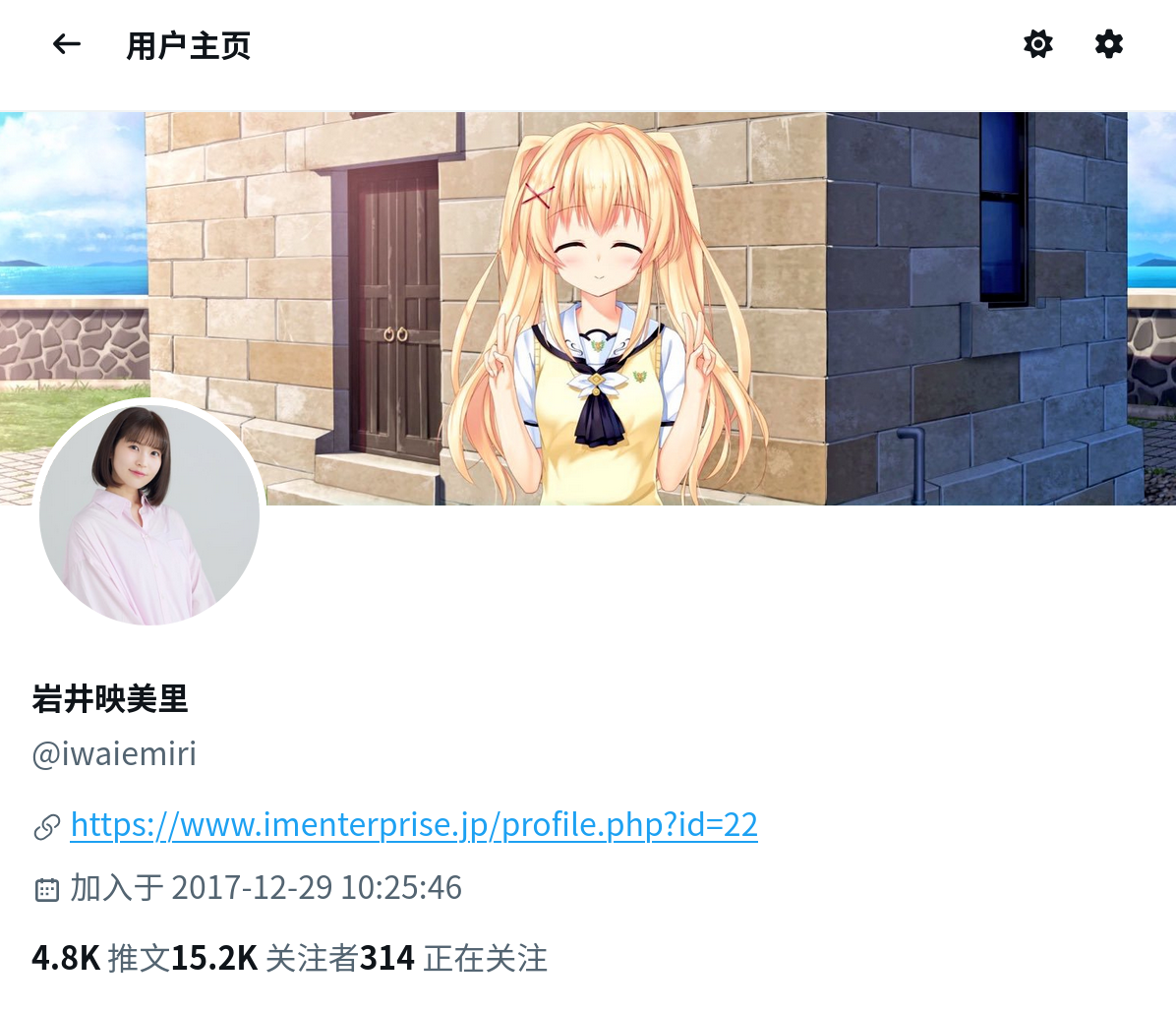
以及涉及到的所有用户的主页信息:
并且这些内容已经全部存储到本地,再也不用担心删号跑路了~

感谢观看🙏
封面图片由Carola68 Die Welt ist bunt……在Pixabay上发布
发表回复